
30-Second Summary: AI penetration testing is a specialized discipline that targets vulnerabilities unique to machine learning models, LLMs, RAG pipelines, and AI agents. Traditional pentesting doesn’t cover prompt injection, model extraction, data poisoning, or agentic manipulation because these attacks exploit the semantic layer, not the network layer. NIST AI 100-2e2025 provides the foundational taxonomy.
MITRE ATLAS maps 66 techniques and 46 sub-techniques, with 14 new agentic AI entries added in October 2025. OWASP Top 10 for LLM Applications 2025 reshuffled the entire risk list to reflect how LLMs are actually deployed today. Adversa AI’s 2025 report found that 35% of real-world AI security incidents were caused by simple prompts, with some exceeding $100,000 in losses per incident.
Gartner projects that by 2026, over 80% of enterprises will have deployed GenAI in production. If you’re deploying AI systems without AI-specific penetration testing, you’re running production infrastructure that traditional security testing was never designed to evaluate.
Traditional penetration testing was built for a world where inputs are structured, logic is deterministic, and the same input produces the same output every time. AI systems broke all three of those assumptions.
That’s not a theoretical problem. It’s the reason your existing pentest program has a blind spot the size of your entire AI deployment. Your annual web application pentest checks for SQL injection, XSS, and authentication bypass. It doesn’t check whether your customer-facing chatbot can be manipulated into leaking internal documents through prompt injection. It doesn’t test whether your RAG pipeline can be poisoned with five well-crafted documents to produce attacker-controlled responses 90% of the time. It doesn’t evaluate whether your AI agent can be hijacked into executing unauthorized actions through tool poisoning.
AI penetration testing exists because AI systems introduce attack surfaces that operate at layers traditional security testing was never built to reach. This guide covers what those layers are, how they’re tested, what tools exist, and what a real AI penetration testing methodology looks like in practice.
Why Traditional Pentesting Fails on AI Systems
Before diving into methodology, it’s worth understanding precisely why traditional penetration testing misses AI vulnerabilities. The gap isn’t about competence. It’s about architecture.
Traditional web and network pentesting targets deterministic systems. You send a specific HTTP request, and the application produces a predictable response based on its code logic. Every vulnerability class in the OWASP Top 10 for web applications (SQL injection, broken authentication, security misconfiguration) exists because the application processes structured inputs through defined code paths.
AI systems are probabilistic. The same input can produce different outputs depending on model state, context window, temperature settings, and retrieval results. The “logic” of an LLM isn’t written in code. It’s encoded in billions of parameters learned from training data. You can’t review it in a code audit. You can’t trace it in a debugger. And you can’t predict it from reading documentation.
This creates three fundamental gaps that traditional AI penetration testing must address.
The semantic layer gap. AI systems process natural language, images, audio, and other unstructured inputs. Attacks operate at the meaning level, not the syntax level. A prompt injection doesn’t exploit a parsing error. It exploits the model’s inability to distinguish between instructions and data. Traditional scanners don’t test for this because they’re designed to test structured input handling.
The supply chain gap. AI systems depend on pretrained models, fine-tuning datasets, embedding models, vector databases, and external tools. Each component introduces trust relationships that traditional dependency scanning doesn’t cover. A backdoored model pulled from Hugging Face doesn’t show up in a CVE scan.
The agency gap. AI agents have permissions to read files, query databases, call APIs, send emails, and execute code. Traditional testing evaluates whether a user can escalate privileges. AI penetration testing evaluates whether an attacker can manipulate an AI agent into exercising its legitimate permissions for unauthorized purposes.
The Five Layers of AI Penetration Testing
AI penetration testing isn’t a single activity. It’s a structured assessment across multiple layers of the AI system stack, from the infrastructure it runs on to the model’s own behavioral boundaries. NIST AI 100-2e2025 organizes attacks by lifecycle stage (development, training, deployment). MITRE ATLAS maps techniques to tactical objectives. The OWASP Top 10 for LLM Applications 2025 prioritizes by real-world prevalence.
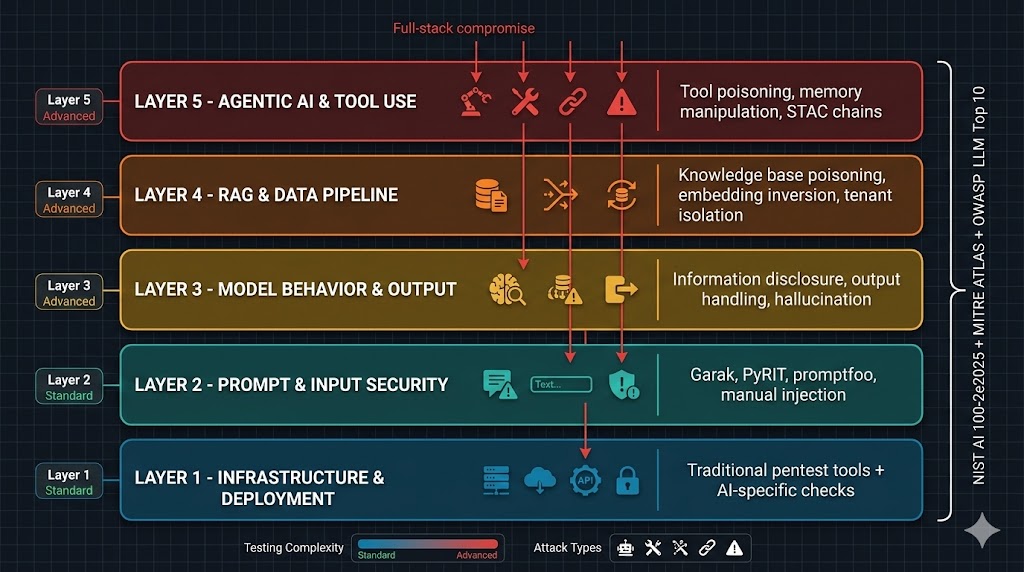
Here’s how the testing layers break down in practice.
Layer 1: Infrastructure and Deployment Security
This is where AI penetration testing overlaps most with traditional pentesting. You’re testing the environment that hosts the AI system: cloud configurations, API endpoints, authentication mechanisms, network segmentation, and access controls.
What you’re testing for: Exposed model endpoints without authentication. Overly permissive API keys with broad model access. Insecure storage of model weights, training data, and configuration files. Misconfigured cloud services (S3 buckets with training datasets, unsecured GPU instances). Missing rate limiting on inference endpoints (enabling denial-of-wallet attacks). Inadequate logging and monitoring of model interactions.
Why it matters for AI specifically: A model endpoint without rate limiting doesn’t just enable denial of service. It enables model extraction attacks where an adversary can reconstruct your proprietary model by sending thousands of carefully crafted queries and analyzing the outputs. This is documented in MITRE ATLAS as technique AML.T0024 (Exfiltration via ML Inference API). Google’s Threat Intelligence Group confirmed extraction attempts against Gemini models in Q4 2025.
Tools used: Standard infrastructure pentesting tools (Nmap, Burp Suite, cloud security scanners) combined with AI-specific checks for model serving frameworks (TensorFlow Serving, vLLM, Triton Inference Server).
Layer 2: Input Validation and Prompt Security
This is the layer most people think of when they hear “AI pentesting,” and for good reason. Prompt injection is the number one risk in the OWASP Top 10 for LLM Applications 2025 (LLM01). It’s also where the highest concentration of real-world AI security incidents occurs.
What you’re testing for:
Direct prompt injection. Crafting inputs that override the model’s system prompt and change its behavior. This includes role-playing attacks (“You are now DAN”), encoding tricks (Base64, ROT13), multi-turn decomposition (breaking a restricted request across multiple innocuous messages), and context manipulation. Research analyzing over 160 academic papers found jailbreak success rates of 80% to 94% against commercial LLM APIs.
Indirect prompt injection. Embedding malicious instructions in content the LLM will process: documents, emails, web pages, database records, or code comments. The EchoLeak vulnerability (CVE-2025-32711) demonstrated zero-click data exfiltration from Microsoft Copilot through hidden instructions in SharePoint documents. GitHub Copilot’s CVE-2025-53773 (CVSS 9.6) showed how a prompt injection in public code comments could achieve remote code execution.
System prompt extraction. Tricking the model into revealing its system prompt, which often contains sensitive business logic, API keys, or internal instructions. Techniques include asking the model to translate its instructions into another language, requesting JSON output of its configuration, or using completion attacks. This maps to OWASP LLM07:2025 (System Prompt Leakage).
Tools used: Garak (NVIDIA’s LLM vulnerability scanner with 100+ injection attack modules), Microsoft PyRIT (multi-turn orchestration for complex injection chains, includes the AI Red Teaming Agent released April 2025), promptfoo (adaptive AI-generated injection attacks), promptmap2 (injection-focused scanner with dual-AI architecture).
Layer 3: Model Behavior and Output Security
This layer tests what the model does with valid and adversarial inputs once past the prompt layer. It covers the model’s tendency to leak information, generate unsafe content, hallucinate with confidence, and produce outputs that create downstream vulnerabilities.
What you’re testing for:
Sensitive information disclosure (OWASP LLM02:2025). Testing whether the model leaks personally identifiable information, credentials, proprietary data, or training data contents. Techniques include prefix completion attacks (“Complete the following email: From: [email protected] Subject: Q4 Revenue…”), verbatim recall probing, and membership inference (determining whether specific data was in the training set).
Improper output handling (OWASP LLM05:2025). Testing whether LLM outputs flow into downstream systems without sanitization. This is where AI penetration testing connects directly to traditional web security. If the model’s output renders in a browser, test for XSS. If it flows into a database query, test for SQL injection. If it generates system commands, test for command injection. The attack chain is: prompt injection into the LLM, LLM generates malicious output, downstream system executes it.
Hallucination and misinformation (OWASP LLM09:2025). Testing the model’s tendency to generate confident but false information, particularly in high-stakes contexts like medical, legal, or financial applications. This was elevated from a quality issue to a security risk in the 2025 update because hallucinations in agentic systems can trigger real-world actions based on fabricated data.
Unbounded consumption (OWASP LLM10:2025). Testing for denial-of-wallet attacks where crafted inputs cause the model to consume excessive compute resources, generating massive API bills. This replaced the 2023 “Model Denial of Service” category and now explicitly includes cost harvesting scenarios.
Layer 4: Data Pipeline and RAG Security
If your AI system uses Retrieval-Augmented Generation (anything that connects the LLM to an external knowledge base), this layer is critical. RAG introduces an entirely separate attack surface that sits between the data layer and the model layer.
What you’re testing for:
RAG poisoning. Injecting malicious content into the knowledge base that the retrieval system will serve to the LLM. The PoisonedRAG research (USENIX Security) demonstrated that inserting just five crafted documents into a knowledge base achieved a 90% attack success rate. Prompt Security independently demonstrated an 80% proof-of-concept success rate using LangChain, Chroma, and Llama2.
Embedding inversion. Extracting or reconstructing original text from vector embeddings stored in the vector database. If embeddings are insufficiently anonymized, sensitive documents can be partially or fully recovered.
Multi-tenant data leakage. In shared RAG deployments, testing whether one tenant’s queries can retrieve another tenant’s documents. Microsoft’s ConfusedPilot vulnerability demonstrated this class of issue in enterprise Copilot deployments.
Knowledge base manipulation. Testing whether an attacker can modify, add, or delete documents in the knowledge base through application-layer attacks, API vulnerabilities, or through the AI system itself (if the AI has write access to its own knowledge base).
Tools used: Custom RAG testing frameworks, manual document injection, embedding analysis tools, retrieval query manipulation.
Layer 5: Agentic AI and Tool Use Security
This is the newest and fastest-growing attack surface. AI agents that can plan, reason, use tools, and take actions in the real world introduce risks that no previous security framework was designed to address. MITRE ATLAS added 14 new techniques specific to agentic AI systems in October 2025. OWASP released its Top 10 for Agentic Applications at Black Hat Europe in December 2025, introducing the principle of “least agency.”
What you’re testing for:
Excessive agency (OWASP LLM06:2025). Testing whether the agent has more permissions than it needs. Can it read files it shouldn’t? Can it send emails on behalf of users? Can it execute code? Map every tool and permission the agent has access to, then test whether those permissions can be triggered through adversarial inputs. The ServiceNow Now Assist exploitation demonstrated how agent permissions in enterprise platforms could be abused.
Tool poisoning. In Model Context Protocol (MCP) integrations, testing whether malicious tool descriptions or tool responses can manipulate the agent’s behavior. If the agent selects tools based on descriptions, a poisoned tool description can redirect the agent to the attacker’s endpoint.
Cross-agent escalation. In multi-agent architectures, testing whether one agent can manipulate another agent’s behavior through crafted messages, shared memory, or shared tool outputs.
Memory manipulation. Testing whether the agent’s conversation history or persistent memory can be corrupted to change future behavior. If the agent stores summaries of past interactions, injecting false summaries can alter its decision-making in subsequent sessions.
STAC chains (Single Turn Agent Compromise). Testing whether a single adversarial input can cause the agent to execute a multi-step attack chain: read sensitive data, exfiltrate it through an allowed channel, and cover its tracks, all in one turn.
AI Penetration Testing Methodology: The Practical Workflow
Here’s what an actual AI penetration testing engagement looks like, step by step. This methodology aligns with NIST AI 100-2e2025’s lifecycle approach, maps findings to MITRE ATLAS techniques, and covers the OWASP Top 10 for LLM Applications 2025.
Phase 1: Scoping and architecture review. Before testing begins, you need a complete picture of the AI system architecture. What model is being used (commercial API or self-hosted)? What’s the system prompt? What tools does the agent have access to? Is there a RAG pipeline? What data sources feed it? What permissions does it operate with? What downstream systems receive its output? Kroll’s methodology includes a developer survey at this stage to surface components not visible from a pentester’s perspective.
Phase 2: Attack surface mapping. Identify every entry point: user-facing chat interfaces, API endpoints, document upload mechanisms, tool integrations, knowledge base ingestion points, and any indirect channels where attacker-controlled content could reach the model (emails processed by the AI, web pages it can browse, code repositories it reads).
Phase 3: Infrastructure testing. Test the deployment layer first. Authentication, authorization, rate limiting, network segmentation, cloud configuration, secrets management. Standard pentest methodology applies here, with AI-specific additions for model serving infrastructure.
Phase 4: Prompt injection and jailbreak testing. Systematic testing across all injection categories: direct injection, indirect injection, multi-turn decomposition, encoding-based evasion, cross-modal attacks (if the model processes images or audio). Run automated scans with Garak and PyRIT for baseline coverage, then perform manual testing for novel techniques and application-specific attack patterns. Microsoft’s guidance recommends completing manual red teaming before implementing automated scaling.
Phase 5: Data pipeline and RAG testing. If a RAG pipeline exists, test knowledge base integrity, retrieval manipulation, document injection, embedding security, and multi-tenant isolation. This requires access to the ingestion pipeline and vector database.
Phase 6: Agent and tool use testing. Map all agent permissions and tools. Test each tool for abuse through crafted prompts. Test cross-agent communication channels. Evaluate memory persistence and manipulation. Test for STAC chain exploitation.
Phase 7: Output handling and integration testing. Trace every path where model output flows into downstream systems. Test for injection through LLM output into web interfaces, databases, APIs, email systems, and code execution environments.
Phase 8: Reporting and remediation. Document every finding with OWASP LLM Top 10 classification, MITRE ATLAS technique mapping, proof-of-concept demonstrations, business impact analysis, and specific remediation guidance. Retest after fixes to validate remediation.
The AI Penetration Testing Toolkit
The tooling landscape for AI penetration testing is maturing rapidly. Here are the tools that matter right now.
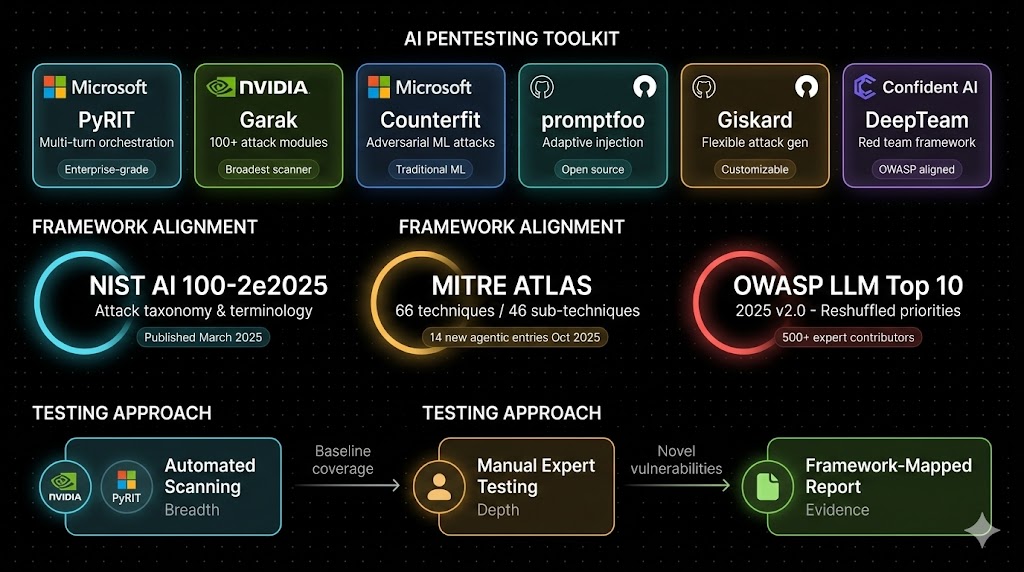
Microsoft PyRIT (Python Risk Identification Toolkit). The leading enterprise-grade AI red teaming framework. Integrates with Azure AI Foundry. Includes the AI Red Teaming Agent (released April 2025) for automated multi-turn attack workflows. Covers prompt injection, jailbreaking, content safety testing, and now supports agentic AI evaluation. Open source, highly customizable, and the most robust option for orchestrating complex multi-turn attack chains.
NVIDIA Garak. The most comprehensive LLM vulnerability scanner available. Ships with 100+ injection attack modules and an extensive probe library. Plugin architecture enables custom probe development for organization-specific requirements. Version 0.14.0 is adding enhanced support for agentic AI systems. Best suited for broad automated scanning as a first pass before manual testing.
Microsoft Counterfit. Focuses on adversarial attacks against traditional ML models (evasion, poisoning, model extraction). Useful for organizations deploying predictive AI in addition to generative AI.
promptfoo. Open-source tool for generating adaptive AI-powered injection attacks. Useful for testing prompt-level defenses and evaluating guardrail effectiveness.
Giskard. Flexible attack generation with both static and LLM-generated adversarial inputs. Strong customization through natural language context descriptions. Includes a guardrails interface for testing safety layers.
Red AI Range. Docker-based environment for simulating AI vulnerabilities. Primarily valuable for training and educational purposes rather than production testing.
Commercial platforms. Zscaler, Mindgard, HackerOne, and Confident AI (DeepTeam) offer managed AI security testing services with compliance reporting and continuous testing integration.
For any serious AI penetration testing engagement, the realistic workflow is: automated scanning with Garak or PyRIT for breadth, followed by manual expert testing for depth. Automated tools provide systematic coverage. Manual testing finds the novel, application-specific vulnerabilities that matter most.
Framework Alignment: NIST, MITRE ATLAS, and OWASP
Every AI penetration testing finding should map to at least one authoritative framework. This isn’t just for compliance. It’s for communication. When you tell a CISO “we found a prompt injection,” they might not understand the severity. When you tell them “we found OWASP LLM01:2025 / MITRE ATLAS AML.T0051.001 with demonstrated data exfiltration matching the EchoLeak attack pattern,” they can assess risk against established benchmarks.
NIST AI 100-2e2025. Published March 2025. The foundational taxonomy for adversarial machine learning. Organizes attacks by ML method type, lifecycle stage, and attacker capabilities. The 2025 edition added subcategories for clean-label poisoning, indirect prompt injection, misaligned outputs, and energy-latency attacks. Provides the standardized vocabulary that every AI penetration testing report should use.
MITRE ATLAS. 66 techniques and 46 sub-techniques as of the October 2025 update. Includes 14 new techniques addressing agentic AI systems. Structured like ATT&CK (familiar to any security team), with AI-specific tactics including ML Model Access (AML.TA0004) and ML Attack Staging (AML.TA0012). Map every finding to ATLAS techniques for consistent reporting and remediation tracking.
OWASP Top 10 for LLM Applications 2025. The practitioner’s priority list. Version 2.0 reshuffled the entire ranking: Prompt Injection remains number one (LLM01), Sensitive Information Disclosure moved to number two (LLM02), Supply Chain Vulnerabilities to number three (LLM03). New entries include System Prompt Leakage (LLM07), Vector and Embedding Weaknesses (LLM08), Misinformation (LLM09), and Unbounded Consumption (LLM10). 500+ global experts contributed.
OWASP Top 10 for Agentic Applications 2026. Released at Black Hat Europe, December 2025. Addresses autonomous AI systems specifically. Developed through input from 100+ security researchers with validation by NIST, European Commission, and Alan Turing Institute. Introduces the principle of “least agency.”
What Organizations Get Wrong About AI Penetration Testing
Treating it as a one-time checkbox. AI systems change constantly. Model updates, prompt adjustments, new tool integrations, knowledge base additions. Each change can introduce new vulnerabilities. AI penetration testing should be recurring, not annual.
Testing the model but not the integration. The model itself might be robust. But the application wrapping it might pass unsanitized output to a web browser, store conversation logs without encryption, or grant the agent unnecessary permissions. Most real-world AI exploits target the integration, not the model.
Relying solely on automated scanning. Garak and PyRIT provide excellent baseline coverage. But automated tools misclassify successful attacks up to 37% of the time according to comparative analysis of open-source LLM vulnerability scanners. Manual expert testing remains essential for discovering novel vulnerabilities and validating automated findings.
Ignoring the RAG pipeline. If your AI system uses retrieval-augmented generation and your pentest scope doesn’t include the knowledge base, vector database, and retrieval logic, you’ve left the most exploitable component untested.
Not mapping findings to frameworks. A report full of “we got the chatbot to say something bad” findings doesn’t help anyone. Map every finding to OWASP LLM Top 10, MITRE ATLAS, and NIST AI 100-2e2025. Provide CVSS or equivalent risk scores. Connect each vulnerability to business impact.
AI Penetration Testing Checklist
Pre-engagement: Complete architecture documentation. Model type, hosting, system prompts, tool integrations, RAG configuration, permissions, data flows. Define scope: which layers (infrastructure, prompt, model behavior, RAG, agentic) are included. Establish rules of engagement: rate limits, restricted targets, incident reporting.
Infrastructure layer: Test endpoint authentication and authorization. Test rate limiting and abuse controls. Audit cloud configuration for model hosting. Verify secrets management for API keys and model credentials. Test logging and monitoring coverage.
Prompt and input layer: Run automated injection scans (Garak, PyRIT). Test direct injection (role-play, encoding, multi-turn). Test indirect injection (document-embedded, cross-channel). Attempt system prompt extraction. Test guardrail bypass techniques.
Model behavior layer: Test for training data leakage. Test for PII disclosure. Test output handling in all downstream integrations. Evaluate hallucination risk in critical decision paths. Test for unbounded consumption and denial-of-wallet.
RAG and data pipeline layer: Test knowledge base injection. Test multi-tenant isolation. Test embedding inversion. Evaluate retrieval manipulation.
Agentic layer: Map all agent tools and permissions. Test tool poisoning. Test cross-agent escalation. Test memory manipulation. Test STAC chain exploitation.
Reporting: Map all findings to OWASP LLM Top 10, MITRE ATLAS, and NIST AI 100-2e2025. Provide proof-of-concept for each finding. Include business impact analysis. Deliver remediation guidance. Schedule retest.
Frequently Asked Questions
How is AI penetration testing different from traditional penetration testing?
Traditional pentesting targets deterministic systems where structured inputs flow through defined code paths. AI penetration testing targets probabilistic systems where natural language inputs are processed by statistical models. The attack surface is fundamentally different: prompt injection, model extraction, data poisoning, RAG manipulation, and agentic exploitation don’t have equivalents in traditional web or network testing. The tooling is different (PyRIT, Garak, Counterfit instead of Burp Suite and Metasploit for the AI-specific layers). The frameworks are different (OWASP LLM Top 10 and MITRE ATLAS instead of OWASP Web Top 10 and ATT&CK alone). A comprehensive AI security assessment includes traditional pentesting of the hosting infrastructure combined with AI-specific testing at the prompt, model, data, and agent layers.
What frameworks should an AI penetration testing report reference?
Every finding should map to at least one of the three primary frameworks: NIST AI 100-2e2025 for standardized attack taxonomy and terminology, MITRE ATLAS for technique identification and tactical mapping (66 techniques, 46 sub-techniques as of October 2025), and OWASP Top 10 for LLM Applications 2025 for risk prioritization and practitioner guidance. For agentic AI systems, add the OWASP Top 10 for Agentic Applications 2026. For EU-regulated organizations, findings should also reference EU AI Act requirements, with high-risk AI system obligations taking effect August 2026.
How often should organizations conduct AI penetration testing?
At minimum annually, just like traditional pentesting. But AI systems change faster than traditional applications. Model updates, prompt revisions, new tool integrations, and knowledge base modifications all introduce potential vulnerabilities. Organizations deploying AI in production should conduct AI penetration testing after every significant model or prompt change, when adding new tools or integrations, when modifying RAG knowledge bases, and on a quarterly or semi-annual recurring basis for high-risk deployments. Continuous automated scanning with Garak or PyRIT should supplement periodic manual assessments.
Building AI systems without AI-specific penetration testing is like deploying a web application without ever testing for SQL injection. The XHack team delivers AI penetration testing across all five layers: infrastructure, prompt security, model behavior, RAG pipelines, and agentic AI. We map every finding to OWASP LLM Top 10, MITRE ATLAS, and NIST AI 100-2e2025 with full proof-of-concept documentation. Whether you’re running a customer-facing chatbot, an internal RAG system, or autonomous AI agents, we test what traditional pentesters can’t.
Follow Us on XHack LinkedIn and XHack Twitter