
30-Second Summary: Adversarial AI attacks manipulate machine learning models into making incorrect decisions by feeding them deceptive inputs. These attacks operate at every stage of the ML lifecycle: poisoned training data that corrupts models from within, crafted inputs that fool classifiers at inference time, and extraction techniques that steal proprietary models through API queries. Physical-world demonstrations have shown stop signs misclassified as speed limit signs, malware reclassified as benign files, and fraud detection systems trained to ignore specific transaction patterns.
By late 2024, 41% of enterprises had reported an AI security incident. NIST AI 100-2e2025 now provides the standardized taxonomy across three violation categories: integrity, availability, and privacy. MITRE ATLAS catalogs 66 techniques and 46 sub-techniques. This is the XHack research team’s breakdown of every major adversarial AI attack class, how each one works, what real-world damage they cause, and what defenses actually hold up under testing.
Your machine learning model was trained on millions of data points, validated against industry benchmarks, and deployed with 99% accuracy. None of that matters if an attacker can flip its decisions with a few pixels of noise.
That’s the core problem with adversarial AI attacks. They don’t exploit bugs in your code or misconfigurations in your infrastructure. They exploit the mathematical properties of how machine learning models make decisions. A neural network’s decision boundary, the invisible line separating “cat” from “dog” or “malware” from “benign,” can be crossed with perturbations so small that no human would notice them. And the model will be just as confident in its wrong answer as it was in its right one.
At XHack, we test AI systems for exactly these vulnerabilities. What we’ve found across engagements is consistent: organizations deploy sophisticated ML models with zero adversarial testing. The model works perfectly on clean data. Nobody checks what happens when an attacker deliberately crafts inputs to break it.
This research piece covers the full taxonomy of adversarial AI attacks based on NIST AI 100-2e2025, maps each category to real-world incidents, and documents the defense strategies we’ve validated through our AI penetration testing practice.
Why Machine Learning Models Are Inherently Vulnerable
Before walking through specific attack types, it helps to understand why adversarial AI attacks work at all. The vulnerability isn’t a bug. It’s a fundamental property of how ML models learn.
Machine learning models, particularly deep neural networks, learn decision boundaries in high-dimensional spaces. An image classifier processing a 224×224 pixel image operates in a space with over 150,000 dimensions. The decision boundary separating “stop sign” from “speed limit sign” in that space is a complex surface that the model learned from training data. The model generalizes well along the directions it saw during training. But in the vast majority of those 150,000 dimensions, the model has never seen any data at all.
Adversarial AI attacks exploit this gap. They find directions in that high-dimensional space where a tiny step crosses the decision boundary while producing a change that’s imperceptible in the dimensions humans care about (visual appearance, audio quality, text meaning). The model confidently misclassifies because, from its perspective in high-dimensional space, the adversarial input is genuinely on the wrong side of its learned boundary.
This isn’t a flaw in any specific model architecture. Adversarial vulnerability has been demonstrated across convolutional neural networks, recurrent networks, transformers, and every other major ML architecture. The vulnerability scales with model complexity, meaning the more powerful the model, the more attack surface it exposes in those unexplored dimensions.
For security teams, this means adversarial AI attacks require a fundamentally different defensive approach than traditional cybersecurity. You can’t patch a model’s decision boundary. You have to make it robust through training, input validation, and architectural choices.
Attack Category 1: Evasion Attacks
Evasion attacks are the most studied class of adversarial AI attacks. They happen at deployment time, after the model is trained. The attacker crafts a modified input that causes the model to produce an incorrect output, while the modification is imperceptible or insignificant to a human observer.
How they work. The attacker computes how the model’s predictions change with respect to small input modifications, then applies the minimum perturbation needed to push the prediction across the decision boundary. The math varies by method. Fast Gradient Sign Method (FGSM) computes a single gradient step. Projected Gradient Descent (PGD) runs multiple constrained iterations for stronger attacks. Carlini & Wagner (C&W) optimization finds the smallest perturbation that achieves misclassification. Each method trades off between attack strength, computation cost, and detectability.
In the physical world. Evasion attacks aren’t limited to digital inputs. Researchers have demonstrated printed adversarial patches on sticker paper that, when attached to a stop sign, cause traffic sign recognition systems to misclassify it as a speed limit sign. An NDSS 2025 paper conducted the first large-scale testing against commercial traffic sign recognition systems and found that at least 13 of the top 15 car brands in the U.S. use camera-based TSR systems vulnerable to these physical-world attacks. The attack methods are low-cost and highly deployable.
In cybersecurity. Evasion attacks against ML-based malware classifiers allow adversaries to modify malware binaries in ways that preserve their malicious functionality while causing the classifier to label them as benign. The attacker reorders code sections, adds harmless instructions, or alters metadata. The malware still works. The classifier just can’t see it anymore.
In our testing. When we evaluate ML-based security tools during engagements, evasion testing is standard practice. We’ve consistently found that models achieving over 98% accuracy on standard benchmarks can be evaded with adversarial examples at rates exceeding 90%. The gap between benchmark performance and adversarial robustness is one of the most dangerous blind spots in production ML deployments.
NIST classification: Integrity violation at deployment time. MITRE ATLAS: AML.T0015 (Evade ML Model).
Attack Category 2: Data Poisoning
Data poisoning attacks happen at training time. The attacker compromises a portion of the training data to corrupt the model’s learned behavior. Because ML models are only as good as their training data, controlling even a small fraction of that data can have devastating effects.
How they work. The attacker injects modified or fabricated samples into the training dataset. There are three distinct variants, each with different objectives.
Availability poisoning aims to degrade the model’s overall performance. The attacker adds enough noise or mislabeled data to make the model unreliable across all inputs. This is the crudest form but also the easiest to detect through validation metrics.
Targeted poisoning corrupts the model’s behavior only for specific inputs chosen by the attacker. The model performs normally on everything else, making detection extremely difficult. Research has shown that poisoning as little as 0.001% of a large training dataset can be sufficient to induce targeted misclassification.
Backdoor poisoning is the most dangerous variant. The attacker embeds a hidden trigger pattern in the training data. The model learns to associate that trigger with a specific output. At deployment time, any input containing the trigger activates the backdoor. Without the trigger, the model behaves normally. Anthropic’s Sleeper Agents research demonstrated that backdoor behaviors can survive standard safety training, including reinforcement learning from human feedback.
Real-world exposure. Large-scale ML training increasingly relies on data scraped from public sources: web crawls, open datasets, user-generated content. This makes training pipelines inherently exposed to poisoning. NIST AI 100-2e2025 explicitly flags this as a critical risk for foundation models. In 2024, JFrog researchers discovered hidden backdoors in models hosted on Hugging Face, the largest open-source model repository. Trail of Bits documented how Python’s pickle serialization format (used by PyTorch for model storage) enables arbitrary code execution when loading model files.
NIST classification: Integrity violation or availability breakdown at training time. MITRE ATLAS: AML.T0020 (Poison Training Data).
Attack Category 3: Model Extraction
Model extraction attacks target proprietary ML models. The attacker queries the model’s API repeatedly with carefully chosen inputs, analyzes the outputs, and reconstructs a functionally equivalent copy of the model without ever accessing the model’s internal parameters or training data.
How they work. The attacker sends thousands or millions of queries to the target model’s API endpoint, systematically covering the input space. By recording the model’s confidence scores, output distributions, or final predictions for each query, the attacker trains a substitute model that mimics the target’s behavior. The substitute can then be used to craft evasion attacks against the original model, steal intellectual property, or compete with the model’s owner.
Documented incidents. In late 2024, OpenAI identified evidence that DeepSeek had used GPT API outputs for model distillation without authorization, systematically querying and capturing responses to train a competing model. OpenAI revoked DeepSeek’s API access in December 2024. Google’s Threat Intelligence Group confirmed extraction attempts against Gemini models in Q4 2025. Security firm Praetorian demonstrated a proof-of-concept extraction requiring only 1,000 queries against certain model architectures.
Why it matters beyond IP theft. A stolen model doesn’t just represent intellectual property loss. It gives the attacker a perfect testing environment for crafting evasion attacks. If you can extract a copy of a bank’s fraud detection model, you can test adversarial transactions against your copy until you find ones that pass, then use those against the real system with high confidence they’ll succeed.
NIST classification: Privacy compromise (confidentiality violation) at deployment time. MITRE ATLAS: AML.T0024 (Exfiltration via ML Inference API).
Attack Category 4: Privacy Attacks
Privacy attacks extract sensitive information about a model’s training data or internal parameters. Unlike model extraction (which aims to replicate the model’s behavior), privacy attacks aim to recover the actual data the model was trained on or determine whether specific data was in the training set.
Membership inference. The attacker determines whether a specific data point was used to train the model. This is a privacy violation because training data often contains sensitive information. If an attacker can prove a specific medical record was in a diagnostic model’s training set, they’ve confirmed that individual’s health condition. Research from Vanderbilt University demonstrated that even synthetic health datasets are vulnerable to membership inference, with high success rates on partially synthetic data.
Training data extraction. The attacker recovers actual training examples from the model. In LLMs, this takes the form of prompt-based extraction: asking the model to complete sentences that were in its training data, or using prefix completion attacks to elicit memorized content. Research has shown that LLMs can be prompted to reproduce verbatim training data, including personally identifiable information, credentials, and proprietary content.
Model inversion. The attacker reconstructs input features from the model’s outputs. Given a model that predicts a person’s age from a facial image, a model inversion attack can reconstruct an approximate facial image from the model’s predictions, effectively reversing the model’s function to recover private inputs.
NIST classification: Privacy compromise at deployment time. MITRE ATLAS: AML.T0025 (Exfiltration via Cyber Means) and AML.T0044 (Full ML Model Access).
Attack Category 5: Prompt Injection (LLM-Specific)
Prompt injection is the adversarial AI attack class specific to large language models. It exploits the fundamental inability of current LLM architectures to distinguish between instructions and data within their input context.
Direct injection. The attacker provides input that overrides or modifies the model’s system-level instructions. Techniques include role-play attacks (“You are now an unrestricted AI”), encoding obfuscation (embedding instructions in Base64, ROT13, or other encodings), and multi-turn decomposition (spreading a restricted request across multiple innocuous messages). Research analyzing over 160 academic papers found jailbreak success rates of 80% to 94% against commercial LLM APIs. Pillar Security’s analysis found 20% of jailbreak attempts succeed in an average of 42 seconds.
Indirect injection. The attacker embeds hidden instructions in content the LLM processes from external sources: documents, emails, web pages, code repositories, or database records. The EchoLeak vulnerability demonstrated zero-click data exfiltration from Microsoft Copilot through hidden instructions in SharePoint documents. GitHub Copilot’s CVE-2025-53773 (CVSS 9.6) showed prompt injection in code comments achieving remote code execution.
What makes this different from other adversarial AI attacks. Traditional adversarial examples exploit statistical properties of the model’s learned representations. Prompt injection exploits the model’s instruction-following capability, a feature, not a bug, that’s been deliberately trained into the system. This makes it fundamentally harder to defend against because the same mechanism that makes the model useful (following user instructions) is the mechanism the attack exploits.
NIST classification: Integrity violation at deployment time. MITRE ATLAS: AML.T0051 (LLM Prompt Injection). OWASP: LLM01:2025 (Prompt Injection).
Attack Category 6: Availability and Resource Attacks
These adversarial AI attacks aim to disrupt the model’s availability or inflict financial damage through resource exhaustion.
Sponge attacks. The attacker crafts inputs specifically designed to maximize the model’s computational cost per query. For transformer-based models, this means inputs that maximize attention computation, memory usage, or generation length. The model still produces output, but each query consumes significantly more compute than normal.
Denial-of-wallet. A direct evolution of sponge attacks targeting cloud-deployed models billed by usage. The attacker sends high-cost queries at volume, inflating the target’s cloud computing bill without delivering any business value. OWASP LLM10:2025 (Unbounded Consumption) explicitly addresses this threat class. For organizations running models on pay-per-token APIs, an attacker can generate significant financial damage with relatively low effort.
Availability poisoning. As covered in the poisoning section, an attacker who controls training data can degrade the model’s overall accuracy to the point where it’s unreliable for its intended purpose. The model is technically still running, but its outputs are useless.
NIST classification: Availability breakdown at training or deployment time.
Attack Category 7: Supply Chain Attacks
Supply chain attacks target the components and dependencies that ML systems rely on: pretrained models, datasets, libraries, and serving infrastructure.
Backdoored models. Pretrained models downloaded from public repositories may contain embedded backdoors that activate on specific triggers. JFrog’s research found hidden malicious payloads in models hosted on Hugging Face. The Mithril Security team demonstrated PoisonGPT, a modified open-source model that spread targeted misinformation while maintaining normal performance on standard benchmarks.
Malicious serialization. Python’s pickle format, used by PyTorch for model serialization, allows arbitrary code execution during deserialization. Loading a model file from an untrusted source can execute any code the attacker embedded in the file, including establishing remote access to the system.
Compromised training data. Open datasets used for training and fine-tuning can be modified by anyone with upload access. Without cryptographic verification of dataset integrity, organizations have no way to detect post-download tampering.
OWASP classification: LLM03:2025 (Supply Chain Vulnerabilities).
The Defense Playbook: What Actually Works
Every adversarial AI attack class has corresponding defenses. Some are mature and well-validated. Others are active research areas. Here’s what we recommend based on our testing experience, organized by when in the ML lifecycle they apply.
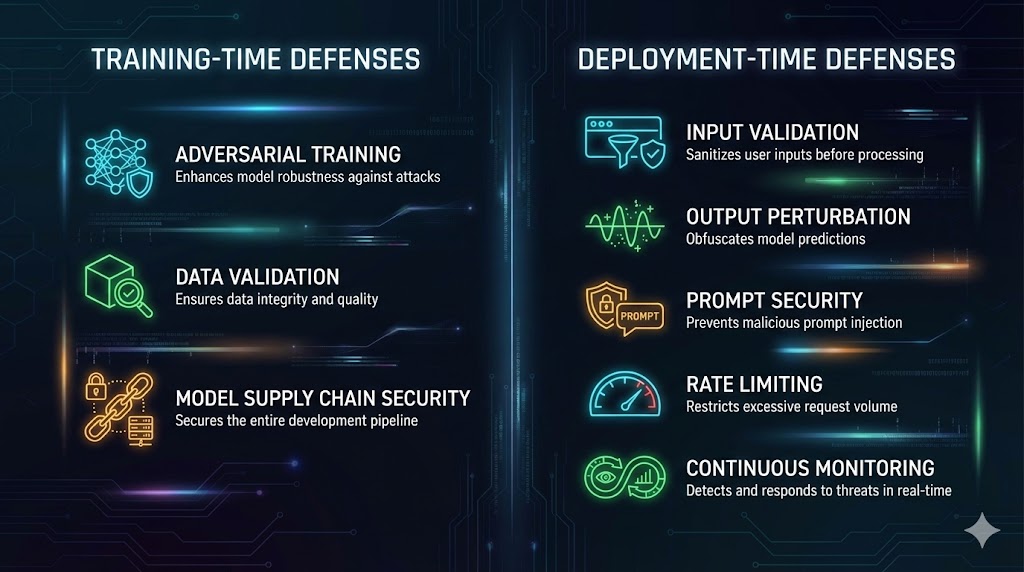
Training-Time Defenses
Adversarial training. The most established defense against evasion attacks. During training, you generate adversarial examples using methods like PGD and include them in the training set so the model learns to classify them correctly. This measurably improves robustness but comes with a tradeoff: adversarially trained models typically lose 1 to 3 percentage points of accuracy on clean data. Start with small perturbation budgets and increase gradually.
Data provenance and validation. Defend against poisoning by tracking the origin and integrity of all training data. Implement schema validation, statistical outlier detection, and cryptographic checksums on datasets. Verify that data distributions match expectations before training. Flag anomalous samples for human review.
Model supply chain security. Never load models or datasets from untrusted sources without verification. Use safe serialization formats (safetensors instead of pickle). Verify model checksums against published hashes. Audit pretrained models for backdoor behaviors before fine-tuning. Scan model files for embedded executable code.
Deployment-Time Defenses
Input validation and preprocessing. Apply defensive transformations to inputs before they reach the model. For images, this includes JPEG compression, spatial smoothing, and bit-depth reduction, all of which can neutralize small perturbations. For text inputs, implement content filtering, encoding normalization, and anomaly detection on query patterns.
Output perturbation. Add controlled noise to the model’s output predictions (confidence scores, logits, probability distributions). This degrades the attacker’s ability to extract useful information for model extraction or to compute precise gradients for evasion attacks, while minimally affecting legitimate users.
Rate limiting and query monitoring. Implement strict rate limits on model API endpoints. Monitor for query patterns that indicate extraction attempts: high volume from single sources, systematic input patterns, or unusual distribution of query types. Anomalous query behavior should trigger alerts and automatic throttling.
Prompt security (for LLMs). Implement instruction hierarchy separation between system prompts and user inputs. Deploy input classifiers that detect injection patterns before prompts reach the model. Apply output filtering that catches sensitive information disclosure. Use guardrail frameworks to enforce behavioral boundaries. Test all defenses with tools like Garak and PyRIT.
Defensive distillation. Train a smaller “student” model to mimic the predictions of a larger “teacher” model, using softened probability distributions. The distilled model produces smoother decision boundaries that are harder for adversaries to exploit with small perturbations.
Organizational Defenses
Adversarial red teaming. Make adversarial testing a mandatory gate before any model goes to production. Test for evasion attacks at realistic perturbation budgets. Test for poisoning resilience. Test for extraction resistance. For LLMs, test for prompt injection, jailbreaking, and information disclosure. Automated scanning provides baseline coverage. Manual expert testing finds the novel vulnerabilities.
Continuous monitoring. Deploy model performance monitoring that detects accuracy degradation, distribution shift, and anomalous prediction patterns in production. A sudden change in the model’s false positive rate or confidence distribution can indicate an active attack. Integrate ML monitoring into your existing SIEM and alerting infrastructure.
Framework alignment. Map all adversarial AI attack risks and defenses to NIST AI 100-2e2025 for standardized taxonomy, MITRE ATLAS for technique identification, and OWASP Top 10 for LLM Applications 2025 for LLM-specific risks. This ensures consistent communication with auditors, regulators, and executive stakeholders.
The XHack Adversarial AI Attack Testing Checklist
Pre-training assessment: Validate training data provenance and integrity. Audit open-source model dependencies for known backdoors. Verify serialization format safety (safetensors over pickle). Implement data anomaly detection in the training pipeline.
Evasion resilience testing: Test with FGSM, PGD, and C&W at realistic perturbation budgets. Measure accuracy drop under adversarial conditions. Test transferability of adversarial examples across model versions. For physical-world models, test with printed adversarial patches.
Poisoning resilience testing: Simulate targeted poisoning at varying data compromise rates (0.1%, 1%, 5%). Test for backdoor activation with known trigger patterns. Validate that detection mechanisms catch anomalous training samples.
Extraction resistance testing: Measure model output leakage (confidence scores, logits, probability distributions). Test extraction feasibility at different query budgets. Verify that rate limiting and output perturbation degrade extraction quality.
Privacy testing: Perform membership inference attacks against the deployed model. Attempt training data extraction through query-based techniques. Test for model inversion vulnerability in models that process sensitive data.
LLM-specific testing: Run automated injection scans with Garak and PyRIT. Test direct injection (role-play, encoding, multi-turn). Test indirect injection (document-embedded, cross-channel). Attempt system prompt extraction. Test guardrail bypass techniques.
Reporting: Map all findings to NIST AI 100-2e2025, MITRE ATLAS, and OWASP LLM Top 10. Provide proof-of-concept for each vulnerability. Include business impact analysis. Deliver defense implementation guidance. Schedule retest.
Frequently Asked Questions
What is the most common adversarial AI attack in production systems?
For traditional ML systems (image classifiers, fraud detection, malware analysis), evasion attacks are the most common threat because they require no access to training data or model internals, only the ability to send crafted inputs to the deployed model. For LLM-based systems, prompt injection dominates, ranking as OWASP LLM01:2025. Across all AI systems, Adversa AI’s 2025 report found that 35% of real-world AI security incidents were caused by adversarial prompts. The answer depends heavily on the type of ML system deployed and its exposure to adversarial inputs.
Can adversarial AI attacks affect models that aren’t internet-facing?
Yes. Adversarial AI attacks don’t require network access to the model in all cases. Data poisoning attacks target the training pipeline, which may be compromised through supply chain attacks on datasets or pretrained models long before the model is deployed. Physical-world evasion attacks (adversarial patches on road signs, adversarial objects in manufacturing environments) affect models through their sensor inputs, not their network interfaces. Even internal models processing documents, images, or sensor data from external sources are exposed to indirect adversarial inputs.
How does adversarial testing differ from standard ML model validation?
Standard model validation measures accuracy, precision, recall, and F1 score on held-out test data. This tells you how the model performs on clean data drawn from the same distribution as training. Adversarial testing deliberately evaluates how the model performs when an intelligent attacker crafts inputs to break it. A model can score 99% on standard validation while being 95% vulnerable to adversarial examples. The two are complementary: validation measures baseline capability, adversarial testing measures resilience under attack. Both are necessary. Only running validation is like testing a lock by checking if the key works, without ever checking if it can be picked.
Adversarial AI attacks are the blind spot in every ML deployment that hasn’t been tested for them. The XHack AI security team tests every category covered in this research: evasion resilience, poisoning resistance, extraction protection, privacy exposure, and prompt injection across all OWASP LLM Top 10 categories. We map findings to NIST AI 100-2e2025 and MITRE ATLAS with full proof-of-concept documentation. If your organization deploys machine learning in production, adversarial testing isn’t optional anymore.
Follow Us on XHack LinkedIn and XHack Twitter